


苹果 x CMU:基于自我中心的机器人避障感知系统(ARMOR)
2025年03月15日
导读
近年来,随着Transformer架构和大语言模型出现突破性进展,业界又重燃了对于人形机器人的应用开发。在实际操作层面,机器人仍然面临多种挑战,例如自主避障和安全问题,以及高自由度所带来的更高难度的策略学习挑战。
解决这些问题的一个关键因素是亟待完善的感知方案。传统的人形机器人感知方案选择在头部或躯干安装高分辨率相机和/或激光雷达。但在许多场景中,手臂和手部感知仍存在遮挡问题。人形机器人在传感和感知能力上的显著差距,使其在密集环境中的运动规划仍面临巨大挑战。
日前,苹果公司(Apple)联合卡内基梅隆大学(CMU)的研究团队提出了一套自我中心感知系统(ARMOR),采用分布式感知方案,通过软、硬件协同增强机器人的“空间意识”,提升人形机器人的避障与运动规划能力。
在经过模仿学习86.6小时的人类真实运动序列之后,研究团队将这套基于Transformer的AI驱动ARMOR-Policy部署在傅利叶GR-1全尺寸人形机器人上进行真实环境测试。最终结果表明,与传统外部感知系统和其他运动规划策略相比,ARMOR在避障和任务成功率方面均有显著提升,验证了该方案的有效性。
相关研究工作
生成无碰撞轨迹对于通用机器人系统的安全部署至关重要。
软件层面,受制于人形机器人在操作空间中展现出的高自由度,要实现无碰撞规划尤为困难。研究人员曾作出多种尝试,已提出的解决策略包括各种基于采样和优化算法、强化学习算法等。
与现有方法不同,研究团队通过在仿真环境中从专家运动规划器提炼出模仿学习(IL)策略,进而推导出一种可扩展的由数据驱动的避障感知策略,可在不同任务和实体之间实现泛化。与此同时,为确保机器人在现实环境中最大限度完成任务,研究人员使用真实的人类运动数据通过模仿学习进行策略训练。
硬件层面,大多数避障规划方法需要固定世界坐标系的感知输入,依赖诸如RGB-D相机等外部传感器,这会限制机器人在动态场景中的应用。相比之下,ARMOR选择将基于自我中心的ToF激光雷达传感器作为基础传感单元遍布机器人的手部和手臂,让机器人获得全方位感知能力。这一设计具有轻量化、低成本、低功耗及可扩展的特点,结合基于Transformer的ARMOR-Policy,能够提升复杂环境下的感知精度和应用范围。
ARMOR系统架构
不同于集中式RGB-D摄像头一次性捕捉密集帧中的全部细节,ARMOR使用了多个SparkFun VL53L5CX ToF激光雷达传感器形成分布式感知网络,为机器人提供了以自我为中心的全方位空间感知。这些传感器的尺寸为6.4×3.0×1.5mm,工作频率可以达到15Hz(某些配置下可达30Hz),拥有8×8的图像分辨率,可以为机器人捕获63°对角视场的深度范围和4000mm视野距离。
研究团队将40个传感器分别安装在傅利叶GR-1人形机器人的两侧手臂和手部,覆盖头部相机的感知盲区。每4个传感器为一组,连接到XIAO ESP微控制器,再通过I2C总线读取数据后,借由USB传输到机器人的机载计算机(Jetson Xavier NX)上。最后,通过无线流式传输至配备NVIDIA GeForce RTX 4090 GPU的Linux主机对数据进行处理。这确保了数据流即使在有多个传感器的设置下,依然能保持15Hz的高效运行速率。

基于模仿学习和Transformer技术,研究团队提出一种动态运动规划策略(ARMOR-Policy),类似基于Transformer的动作分块策略(ACT)。通过使用AMASS数据集(包含86.6小时的311,922条人类运动数据),ARMOR学习了如何在复杂环境中避障和规划运动。该策略直接利用ToF传感器生成的3D点云输入,无需额外的预处理步骤。
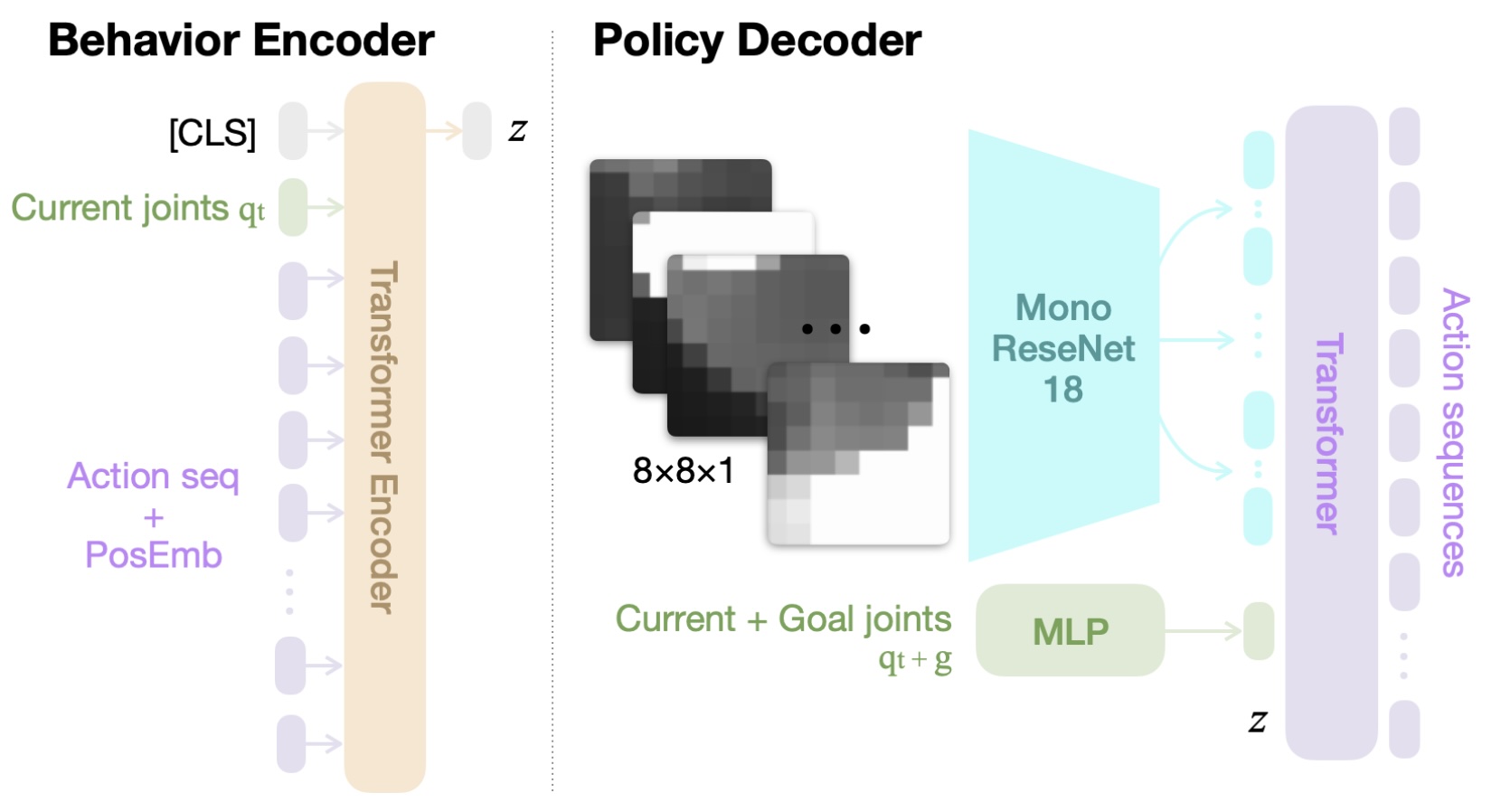
为了确保安全运动规划,研发团队实现了轻量级的推理时间优化。ARMOR-Policy通过调整潜在变量输出多个轨迹,再利用符号距离函数(SDF)计算轨迹与点云(PCL)的最小距离,选出最优路径以实现无碰撞规划。
无碰撞运动规划实验与结果
为了评估ARMOR自我中心感知方法在避障中的表现,以及ACT策略的神经运动规划架构对自我中心感知的有效性,研发团队分别在仿真环境和傅利叶GR-1人形机器人上部署ARMOR感知系统和ARMOR ACT策略,进行双上肢无碰撞运动规划评估测试。
实验设置
在仿真环境中对基于自我中心的ARMOR传感器阵列和外部相机两种感知方案进行评估,分别使用VL53L5CX ToF深度传感器和Intel RealSense D435外部相机。基于311,922个动作训练ACT策略,并在另外66,840个实例上进行验证。在实验评估中仅保留存在解决方案且场景中有障碍物的运动序列,从中产生了22,280个用于测试的运动序列。
实验结果
实验比较了ARMOR自我中心感知系统与外部感知系统,以及ACT策略与基于采样的运动规划策略cuRobo,并评估加入推理时间优化的ARMOR-Policy的优势。同时实验定义了三个性能指标:导致碰撞的机器人与障碍物接触次数、成功到达目标姿势的序列数以及推理计算时间。
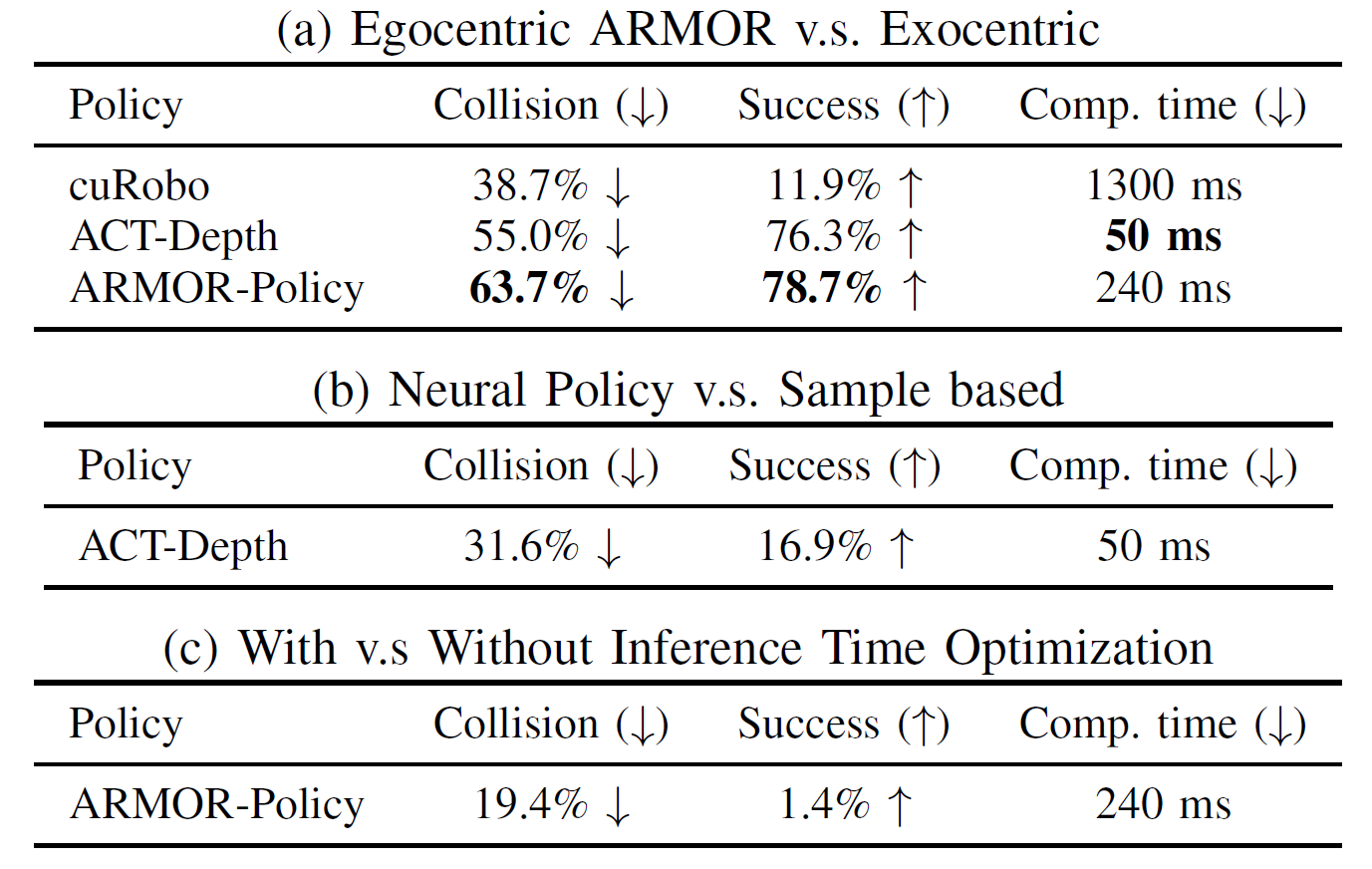
(a)ARMOR自我中心感知与外部感知比较,(b)ACT-Depth策略与cuRobo策略比较,(c)加入推理时间优化后的性能提升
ARMOR自我中心感知 vs.外部感知
采用cuRobo、ACT和ARMOR-Policy三种策略验证ARMOR自我中心感知系统与外部感知系统的性能。表1(a)总结了相较于外部感知,每种策略下ARMOR感知的性能改善均优于外部感知。例如,当ARMOR-Policy使用ARMOR感知时,相较于外部感知,碰撞减少了63.7%,成功率提高了78.7%。
ACT策略 vs. cuRobo基准策略
将基于Transformer的ACT策略与基于采样的cuRobo基准策略进行比较。表1(b)显示了在使用ARMOR感知的情况下,对比cuRobo基准策略,没有推理时间优化的ACT策略的碰撞减少了31.6%,成功实例增加了16.9%,计算速度提高近26倍。
推理时间优化的优势
与没有推理时间优化的ACT策略相比,具有轻量级推理时间优化的ARMOR-Policy的碰撞进一步减少了19.4%,成功率提高了1.4%。
真实环境部署
研究团队在傅利叶GR-1上部署了带有28个ToF激光雷达传感器的ARMOR感知系统,展示了ARMOR-Policy在循环中的实时部署,用于避障,并以15Hz的频率(与ToF更新频率一致)更新轨迹。
结论
ARMOR感知系统涵盖硬件和软件创新,利用可穿戴传感器实现人形机器人操控中的无遮挡自我感知,ARMOR-Policy支持敏捷的机器人运动轨迹,在复杂环境中作为计算高效的无碰撞运动规划器而发挥作用,同时验证了自我中心感知对比外部感知的有效性。
论文链接:https://arxiv.org/abs/2412.00396
项目主页:https://daehwakim.com/armor/
傅利叶支持并推动具身智能的研究探索,通过与全球最头部的科技公司和顶尖科研院校开展交流与合作,加速人形机器人技术的创新与应用,促进AI与物理世界的融合发展。
Contact Us
生态合作:generalrobot@fftai.com
人才招聘:job@fftai.com

